Deploy your own code helper!
The methods described in this article may be subject to time sensitivity.
Environment
Key
Value
CPU
AMD Ryzen R9-5950X
GPU
Nvidia RTX 2080Ti 22G
RAM
32G x 2 3200MHz
OS
Windows 10 22H2
Driver
537.58
CUDA
12.0
conda
4.10.3
Python
3.10.6
Pytorch
2.1.0
Attempts on Windows
For some well-known reasons, the installation steps require resolving various network issues, and this article will not specifically discuss these details.
Before You Begin Repository Address: https://github.com/THUDM/CodeGeeX2
All subsequent steps are performed in the directory of the cloned project.
Installing PyTorch It is assumed that you have already created a conda environment using Python 3.10. All operations will be carried out within this environment. Follow the instructions provided on the PyTorch official website to install the conda environment.
1 pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
Install the requirements specified by requirements.txt 1 pip install -r requirements.txt
YDJSIR encountered a specific issue here. It seems that the code installed via pip is not the latest version and has some bugs. You can manually update the corresponding files. Reference link: https://github.com/chatchat-space/Langchain-Chatchat/issues/1835 .
Since the 20 series does not support bf16, you need to modify the code according to the instructions in README.md.
Install chatglm-cpp Please first install Visual Studio 2022; the Community Edition is sufficient, and you can also choose to install only the build tools. It has been tested that VS 2017 does not work. Reference link:
https://blog.csdn.net/fanyingkk/article/details/131192374
After that, execute the following command (in PowerShell). Reference link: https://github.com/li-plus/chatglm.cpp/issues/124
1 2 3 $env :TRACKFILEACCESS="false" set "CMAKE_ARGS=-DGGML_CUBLAS=ON" pip install chatglm-cpp
Install fastllm?
It seems that directly installing on Windows does not allow for the direct activation; when using fastllm, you still encounter an exception and fall back to a state without fastllm enabled. Additionally, the method of self-compiling on Windows is also not functional.
https://github.com/ztxz16/fastllm
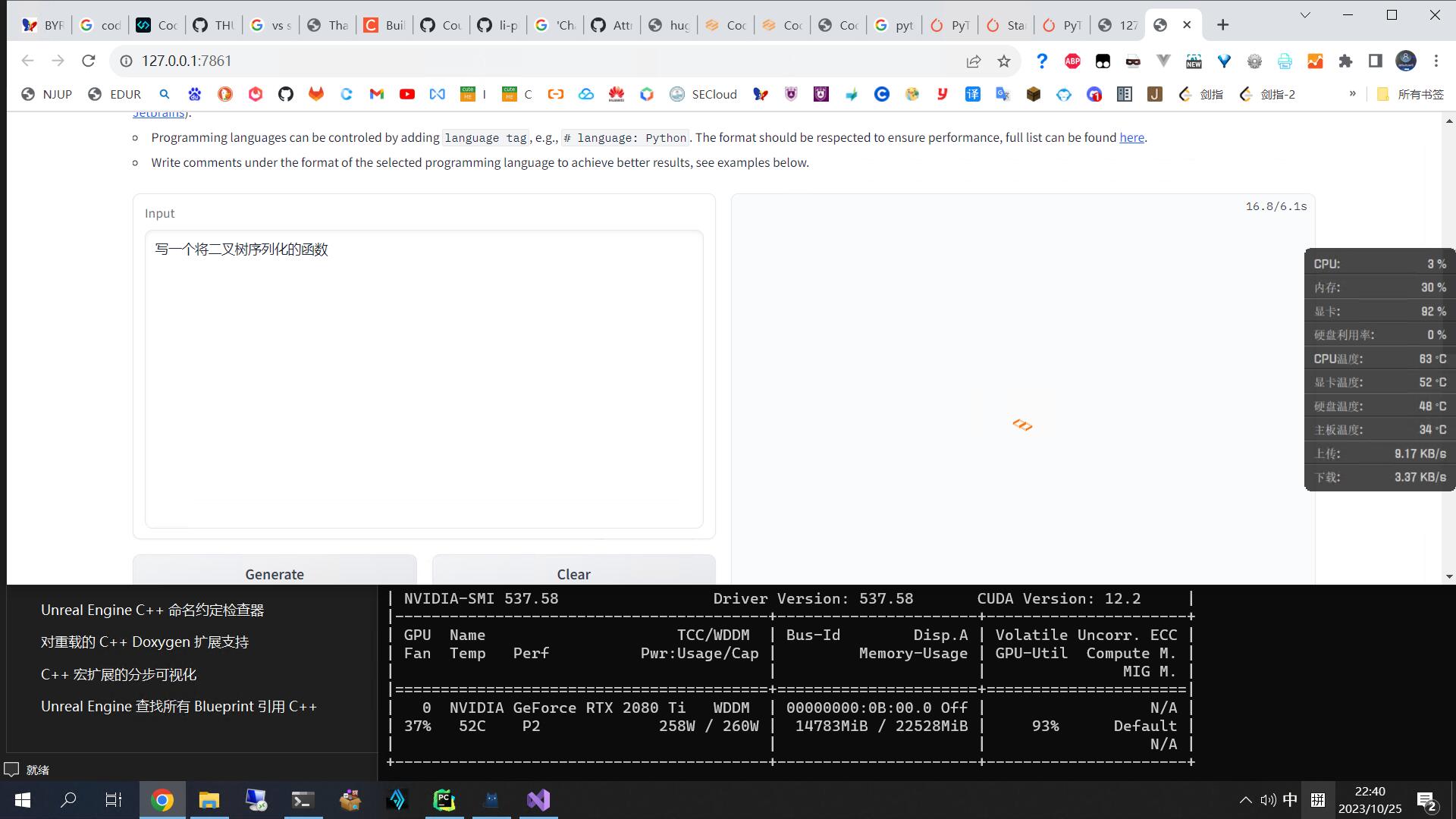
gradio, Start!Run demo/run_demo.py from the project. The first execution will pull the model from Hugging Face, which may take some time. Once started, you can enjoy experiencing CodeGeex2 in your web browser!
1 python ./demo/run_demo.py
The --fastllm parameter currently seems to be unavailable; it still shows as disabled when used.
When using the --chatglm-cpp parameter, running it in administrator mode on Windows still encounters file permission issues. This is still under investigation.
Without these two parameters, the program can start, but it runs quite slowly.
1 2 3 4 5 6 7 8 9 (CodeGeeX2) PS F:\model\CodeGeeX2> python ./demo/run_demo.py fastllm disabled. Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:04<00:00, 1.71it/s] chatglm-cpp and fastllm not installed, using transformers. Running on local URL: http://127.0.0.1:7861 To create a public link, set `share=True` in `launch()`. Keyboard interruption in main thread... closing server.
Quick Start on WSL 2 Before You Begin This section uses WSL 2 on a Windows 10 22H2 Professional Workstation operating system. WSL 2 can read Windows files, so the previously cloned project can be used directly. Therefore, the modifications mentioned in previous sections are also applicable here. Below is the WSL version information.
In this version, WSL can access the GPU and run GUI-enabled Linux applications, providing a very good experience.
First, let’s update WSL to the latest version. Please run this in administrator mode.
1 2 wsl --shutdown wsl --update
As long as the Windows and WSL versions are compatible, enabling the GPU in WSL is not a difficult task. The key lies in the operations within WSL itself. The official documentation mainly describes the operations on the Windows side.
WSL GPU Support Documentation
It is well-known that WSL2 has a very independent network. In this special network environment, many things can be quite challenging. Therefore, YDJSIR tries to prepare everything on Windows before operating in WSL. Here are a few documents for reference. During YDJSIR’s actual operation, a driver was tested before proceeding with CUDA installation.
https://docs.nvidia.com/cuda/wsl-user-guide/index.html#getting-started-with-cuda-on-wsl
https://developer.nvidia.com/cuda-downloads?target_os=Linux&target_arch=x86_64&Distribution=WSL-Ubuntu&target_version=2.0&target_type=deb_local
By the way, you may find that a lot of tools are missing later on, such as unzip, since WSL is quite minimal. Just install whatever is needed.
Installing PyTorch The installation process is pretty much the same as before.
Installing Dependencies from requirements.txt This process is exactly the same as previously mentioned, but there is one important note: the version of the transformers library must be locked to 4.33. For more details, refer to the following link:
Hugging Face Discussion on Transformers Version
You can install this package separately.
1 pip install transformers==4.33.0
Installing chatglm-cpp The installation under WSL was successful on the first attempt. I tested it out, and when running on the CPU (without the preceding parameters), the default configuration takes about 40 seconds to generate, but the AMD Ryzen R9-5950X only utilized half of its capacity. When using the GPU, it takes around 4 seconds.
1 CMAKE_ARGS="-DGGML_CUBLAS=ON" pip install chatglm-cpp -i https://pypi.mirrors.ustc.edu.cn/simple/ --force-reinstall -v --no-cache
gradio, Start!Run demo/run_demo.py from the project. The first execution will pull the model from Hugging Face, which may take some time. YDJSIR chose to download all the files directly from https://huggingface.co/docs/huggingface_hub/v0.19.3/guides/download (using Git LFS) and placed them in the default download location that Hugging Face uses (for more details, refer to https://zhuanlan.zhihu.com/p/475260268 ). Once started, you can enjoy experiencing CodeGeex2 in your web browser!
1 python ./demo/run_demo.py --chatglm-cpp
The --fastllm parameter currently seems to be unavailable; it still shows as disabled when used.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 (CodeGeex) ydjsir@YDJ-Z490UD:/mnt/f/model/CodeGeeX2$ python ./demo/run_demo.py --chatglm-cpp fastllm disabled. Using chatglm-cpp to improve performance Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████| 7/7 [00:06<00:00, 1.08it/s]Processing model states: 100%|███████████████████████████████████████████████████████████| 199/199 [00:09<00:00, 21.84it/s]+---------------------------------------------------------------------+---------------------------+---------+ | name | shape | dtype | |---------------------------------------------------------------------+---------------------------+---------| | transformer.embedding.word_embeddings.weight | torch.Size([65024, 4096]) | F16 | | transformer.encoder.layers.0.input_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.0.self_attention.query_key_value.weight | torch.Size([4608, 4096]) | F16 | | transformer.encoder.layers.0.self_attention.query_key_value.bias | torch.Size([4608]) | F32 | | transformer.encoder.layers.0.self_attention.dense.weight | torch.Size([4096, 4096]) | F16 | | transformer.encoder.layers.0.post_attention_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.0.mlp.dense_h_to_4h.weight | torch.Size([27392, 4096]) | F16 | | transformer.encoder.layers.0.mlp.dense_4h_to_h.weight | torch.Size([4096, 13696]) | F16 | | transformer.encoder.layers.1.input_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.1.self_attention.query_key_value.weight | torch.Size([4608, 4096]) | F16 | | transformer.encoder.layers.1.self_attention.query_key_value.bias | torch.Size([4608]) | F32 | | transformer.encoder.layers.1.self_attention.dense.weight | torch.Size([4096, 4096]) | F16 | | transformer.encoder.layers.1.post_attention_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.1.mlp.dense_h_to_4h.weight | torch.Size([27392, 4096]) | F16 | | transformer.encoder.layers.1.mlp.dense_4h_to_h.weight | torch.Size([4096, 13696]) | F16 | | transformer.encoder.layers.2.input_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.2.self_attention.query_key_value.weight | torch.Size([4608, 4096]) | F16 | | transformer.encoder.layers.2.self_attention.query_key_value.bias | torch.Size([4608]) | F32 | | transformer.encoder.layers.2.self_attention.dense.weight | torch.Size([4096, 4096]) | F16 | | transformer.encoder.layers.2.post_attention_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.2.mlp.dense_h_to_4h.weight | torch.Size([27392, 4096]) | F16 | | transformer.encoder.layers.2.mlp.dense_4h_to_h.weight | torch.Size([4096, 13696]) | F16 | | transformer.encoder.layers.3.input_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.3.self_attention.query_key_value.weight | torch.Size([4608, 4096]) | F16 | | transformer.encoder.layers.3.self_attention.query_key_value.bias | torch.Size([4608]) | F32 | | transformer.encoder.layers.3.self_attention.dense.weight | torch.Size([4096, 4096]) | F16 | | transformer.encoder.layers.3.post_attention_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.3.mlp.dense_h_to_4h.weight | torch.Size([27392, 4096]) | F16 | | transformer.encoder.layers.3.mlp.dense_4h_to_h.weight | torch.Size([4096, 13696]) | F16 | | transformer.encoder.layers.4.input_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.4.self_attention.query_key_value.weight | torch.Size([4608, 4096]) | F16 | | transformer.encoder.layers.4.self_attention.query_key_value.bias | torch.Size([4608]) | F32 | | transformer.encoder.layers.4.self_attention.dense.weight | torch.Size([4096, 4096]) | F16 | | transformer.encoder.layers.4.post_attention_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.4.mlp.dense_h_to_4h.weight | torch.Size([27392, 4096]) | F16 | | transformer.encoder.layers.4.mlp.dense_4h_to_h.weight | torch.Size([4096, 13696]) | F16 | | transformer.encoder.layers.5.input_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.5.self_attention.query_key_value.weight | torch.Size([4608, 4096]) | F16 | | transformer.encoder.layers.5.self_attention.query_key_value.bias | torch.Size([4608]) | F32 | | transformer.encoder.layers.5.self_attention.dense.weight | torch.Size([4096, 4096]) | F16 | | transformer.encoder.layers.5.post_attention_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.5.mlp.dense_h_to_4h.weight | torch.Size([27392, 4096]) | F16 | | transformer.encoder.layers.5.mlp.dense_4h_to_h.weight | torch.Size([4096, 13696]) | F16 | | transformer.encoder.layers.6.input_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.6.self_attention.query_key_value.weight | torch.Size([4608, 4096]) | F16 | | transformer.encoder.layers.6.self_attention.query_key_value.bias | torch.Size([4608]) | F32 | | transformer.encoder.layers.6.self_attention.dense.weight | torch.Size([4096, 4096]) | F16 | | transformer.encoder.layers.6.post_attention_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.6.mlp.dense_h_to_4h.weight | torch.Size([27392, 4096]) | F16 | | transformer.encoder.layers.6.mlp.dense_4h_to_h.weight | torch.Size([4096, 13696]) | F16 | | transformer.encoder.layers.7.input_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.7.self_attention.query_key_value.weight | torch.Size([4608, 4096]) | F16 | | transformer.encoder.layers.7.self_attention.query_key_value.bias | torch.Size([4608]) | F32 | | transformer.encoder.layers.7.self_attention.dense.weight | torch.Size([4096, 4096]) | F16 | | transformer.encoder.layers.7.post_attention_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.7.mlp.dense_h_to_4h.weight | torch.Size([27392, 4096]) | F16 | | transformer.encoder.layers.7.mlp.dense_4h_to_h.weight | torch.Size([4096, 13696]) | F16 | | transformer.encoder.layers.8.input_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.8.self_attention.query_key_value.weight | torch.Size([4608, 4096]) | F16 | | transformer.encoder.layers.8.self_attention.query_key_value.bias | torch.Size([4608]) | F32 | | transformer.encoder.layers.8.self_attention.dense.weight | torch.Size([4096, 4096]) | F16 | | transformer.encoder.layers.8.post_attention_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.8.mlp.dense_h_to_4h.weight | torch.Size([27392, 4096]) | F16 | | transformer.encoder.layers.8.mlp.dense_4h_to_h.weight | torch.Size([4096, 13696]) | F16 | | transformer.encoder.layers.9.input_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.9.self_attention.query_key_value.weight | torch.Size([4608, 4096]) | F16 | | transformer.encoder.layers.9.self_attention.query_key_value.bias | torch.Size([4608]) | F32 | | transformer.encoder.layers.9.self_attention.dense.weight | torch.Size([4096, 4096]) | F16 | | transformer.encoder.layers.9.post_attention_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.9.mlp.dense_h_to_4h.weight | torch.Size([27392, 4096]) | F16 | | transformer.encoder.layers.9.mlp.dense_4h_to_h.weight | torch.Size([4096, 13696]) | F16 | | transformer.encoder.layers.10.input_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.10.self_attention.query_key_value.weight | torch.Size([4608, 4096]) | F16 | | transformer.encoder.layers.10.self_attention.query_key_value.bias | torch.Size([4608]) | F32 | | transformer.encoder.layers.10.self_attention.dense.weight | torch.Size([4096, 4096]) | F16 | | transformer.encoder.layers.10.post_attention_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.10.mlp.dense_h_to_4h.weight | torch.Size([27392, 4096]) | F16 | | transformer.encoder.layers.10.mlp.dense_4h_to_h.weight | torch.Size([4096, 13696]) | F16 | | transformer.encoder.layers.11.input_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.11.self_attention.query_key_value.weight | torch.Size([4608, 4096]) | F16 | | transformer.encoder.layers.11.self_attention.query_key_value.bias | torch.Size([4608]) | F32 | | transformer.encoder.layers.11.self_attention.dense.weight | torch.Size([4096, 4096]) | F16 | | transformer.encoder.layers.11.post_attention_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.11.mlp.dense_h_to_4h.weight | torch.Size([27392, 4096]) | F16 | | transformer.encoder.layers.11.mlp.dense_4h_to_h.weight | torch.Size([4096, 13696]) | F16 | | transformer.encoder.layers.12.input_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.12.self_attention.query_key_value.weight | torch.Size([4608, 4096]) | F16 | | transformer.encoder.layers.12.self_attention.query_key_value.bias | torch.Size([4608]) | F32 | | transformer.encoder.layers.12.self_attention.dense.weight | torch.Size([4096, 4096]) | F16 | | transformer.encoder.layers.12.post_attention_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.12.mlp.dense_h_to_4h.weight | torch.Size([27392, 4096]) | F16 | | transformer.encoder.layers.12.mlp.dense_4h_to_h.weight | torch.Size([4096, 13696]) | F16 | | transformer.encoder.layers.13.input_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.13.self_attention.query_key_value.weight | torch.Size([4608, 4096]) | F16 | | transformer.encoder.layers.13.self_attention.query_key_value.bias | torch.Size([4608]) | F32 | | transformer.encoder.layers.13.self_attention.dense.weight | torch.Size([4096, 4096]) | F16 | | transformer.encoder.layers.13.post_attention_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.13.mlp.dense_h_to_4h.weight | torch.Size([27392, 4096]) | F16 | | transformer.encoder.layers.13.mlp.dense_4h_to_h.weight | torch.Size([4096, 13696]) | F16 | | transformer.encoder.layers.14.input_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.14.self_attention.query_key_value.weight | torch.Size([4608, 4096]) | F16 | | transformer.encoder.layers.14.self_attention.query_key_value.bias | torch.Size([4608]) | F32 | | transformer.encoder.layers.14.self_attention.dense.weight | torch.Size([4096, 4096]) | F16 | | transformer.encoder.layers.14.post_attention_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.14.mlp.dense_h_to_4h.weight | torch.Size([27392, 4096]) | F16 | | transformer.encoder.layers.14.mlp.dense_4h_to_h.weight | torch.Size([4096, 13696]) | F16 | | transformer.encoder.layers.15.input_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.15.self_attention.query_key_value.weight | torch.Size([4608, 4096]) | F16 | | transformer.encoder.layers.15.self_attention.query_key_value.bias | torch.Size([4608]) | F32 | | transformer.encoder.layers.15.self_attention.dense.weight | torch.Size([4096, 4096]) | F16 | | transformer.encoder.layers.15.post_attention_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.15.mlp.dense_h_to_4h.weight | torch.Size([27392, 4096]) | F16 | | transformer.encoder.layers.15.mlp.dense_4h_to_h.weight | torch.Size([4096, 13696]) | F16 | | transformer.encoder.layers.16.input_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.16.self_attention.query_key_value.weight | torch.Size([4608, 4096]) | F16 | | transformer.encoder.layers.16.self_attention.query_key_value.bias | torch.Size([4608]) | F32 | | transformer.encoder.layers.16.self_attention.dense.weight | torch.Size([4096, 4096]) | F16 | | transformer.encoder.layers.16.post_attention_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.16.mlp.dense_h_to_4h.weight | torch.Size([27392, 4096]) | F16 | | transformer.encoder.layers.16.mlp.dense_4h_to_h.weight | torch.Size([4096, 13696]) | F16 | | transformer.encoder.layers.17.input_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.17.self_attention.query_key_value.weight | torch.Size([4608, 4096]) | F16 | | transformer.encoder.layers.17.self_attention.query_key_value.bias | torch.Size([4608]) | F32 | | transformer.encoder.layers.17.self_attention.dense.weight | torch.Size([4096, 4096]) | F16 | | transformer.encoder.layers.17.post_attention_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.17.mlp.dense_h_to_4h.weight | torch.Size([27392, 4096]) | F16 | | transformer.encoder.layers.17.mlp.dense_4h_to_h.weight | torch.Size([4096, 13696]) | F16 | | transformer.encoder.layers.18.input_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.18.self_attention.query_key_value.weight | torch.Size([4608, 4096]) | F16 | | transformer.encoder.layers.18.self_attention.query_key_value.bias | torch.Size([4608]) | F32 | | transformer.encoder.layers.18.self_attention.dense.weight | torch.Size([4096, 4096]) | F16 | | transformer.encoder.layers.18.post_attention_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.18.mlp.dense_h_to_4h.weight | torch.Size([27392, 4096]) | F16 | | transformer.encoder.layers.18.mlp.dense_4h_to_h.weight | torch.Size([4096, 13696]) | F16 | | transformer.encoder.layers.19.input_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.19.self_attention.query_key_value.weight | torch.Size([4608, 4096]) | F16 | | transformer.encoder.layers.19.self_attention.query_key_value.bias | torch.Size([4608]) | F32 | | transformer.encoder.layers.19.self_attention.dense.weight | torch.Size([4096, 4096]) | F16 | | transformer.encoder.layers.19.post_attention_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.19.mlp.dense_h_to_4h.weight | torch.Size([27392, 4096]) | F16 | | transformer.encoder.layers.19.mlp.dense_4h_to_h.weight | torch.Size([4096, 13696]) | F16 | | transformer.encoder.layers.20.input_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.20.self_attention.query_key_value.weight | torch.Size([4608, 4096]) | F16 | | transformer.encoder.layers.20.self_attention.query_key_value.bias | torch.Size([4608]) | F32 | | transformer.encoder.layers.20.self_attention.dense.weight | torch.Size([4096, 4096]) | F16 | | transformer.encoder.layers.20.post_attention_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.20.mlp.dense_h_to_4h.weight | torch.Size([27392, 4096]) | F16 | | transformer.encoder.layers.20.mlp.dense_4h_to_h.weight | torch.Size([4096, 13696]) | F16 | | transformer.encoder.layers.21.input_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.21.self_attention.query_key_value.weight | torch.Size([4608, 4096]) | F16 | | transformer.encoder.layers.21.self_attention.query_key_value.bias | torch.Size([4608]) | F32 | | transformer.encoder.layers.21.self_attention.dense.weight | torch.Size([4096, 4096]) | F16 | | transformer.encoder.layers.21.post_attention_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.21.mlp.dense_h_to_4h.weight | torch.Size([27392, 4096]) | F16 | | transformer.encoder.layers.21.mlp.dense_4h_to_h.weight | torch.Size([4096, 13696]) | F16 | | transformer.encoder.layers.22.input_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.22.self_attention.query_key_value.weight | torch.Size([4608, 4096]) | F16 | | transformer.encoder.layers.22.self_attention.query_key_value.bias | torch.Size([4608]) | F32 | | transformer.encoder.layers.22.self_attention.dense.weight | torch.Size([4096, 4096]) | F16 | | transformer.encoder.layers.22.post_attention_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.22.mlp.dense_h_to_4h.weight | torch.Size([27392, 4096]) | F16 | | transformer.encoder.layers.22.mlp.dense_4h_to_h.weight | torch.Size([4096, 13696]) | F16 | | transformer.encoder.layers.23.input_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.23.self_attention.query_key_value.weight | torch.Size([4608, 4096]) | F16 | | transformer.encoder.layers.23.self_attention.query_key_value.bias | torch.Size([4608]) | F32 | | transformer.encoder.layers.23.self_attention.dense.weight | torch.Size([4096, 4096]) | F16 | | transformer.encoder.layers.23.post_attention_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.23.mlp.dense_h_to_4h.weight | torch.Size([27392, 4096]) | F16 | | transformer.encoder.layers.23.mlp.dense_4h_to_h.weight | torch.Size([4096, 13696]) | F16 | | transformer.encoder.layers.24.input_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.24.self_attention.query_key_value.weight | torch.Size([4608, 4096]) | F16 | | transformer.encoder.layers.24.self_attention.query_key_value.bias | torch.Size([4608]) | F32 | | transformer.encoder.layers.24.self_attention.dense.weight | torch.Size([4096, 4096]) | F16 | | transformer.encoder.layers.24.post_attention_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.24.mlp.dense_h_to_4h.weight | torch.Size([27392, 4096]) | F16 | | transformer.encoder.layers.24.mlp.dense_4h_to_h.weight | torch.Size([4096, 13696]) | F16 | | transformer.encoder.layers.25.input_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.25.self_attention.query_key_value.weight | torch.Size([4608, 4096]) | F16 | | transformer.encoder.layers.25.self_attention.query_key_value.bias | torch.Size([4608]) | F32 | | transformer.encoder.layers.25.self_attention.dense.weight | torch.Size([4096, 4096]) | F16 | | transformer.encoder.layers.25.post_attention_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.25.mlp.dense_h_to_4h.weight | torch.Size([27392, 4096]) | F16 | | transformer.encoder.layers.25.mlp.dense_4h_to_h.weight | torch.Size([4096, 13696]) | F16 | | transformer.encoder.layers.26.input_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.26.self_attention.query_key_value.weight | torch.Size([4608, 4096]) | F16 | | transformer.encoder.layers.26.self_attention.query_key_value.bias | torch.Size([4608]) | F32 | | transformer.encoder.layers.26.self_attention.dense.weight | torch.Size([4096, 4096]) | F16 | | transformer.encoder.layers.26.post_attention_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.26.mlp.dense_h_to_4h.weight | torch.Size([27392, 4096]) | F16 | | transformer.encoder.layers.26.mlp.dense_4h_to_h.weight | torch.Size([4096, 13696]) | F16 | | transformer.encoder.layers.27.input_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.27.self_attention.query_key_value.weight | torch.Size([4608, 4096]) | F16 | | transformer.encoder.layers.27.self_attention.query_key_value.bias | torch.Size([4608]) | F32 | | transformer.encoder.layers.27.self_attention.dense.weight | torch.Size([4096, 4096]) | F16 | | transformer.encoder.layers.27.post_attention_layernorm.weight | torch.Size([4096]) | F32 | | transformer.encoder.layers.27.mlp.dense_h_to_4h.weight | torch.Size([27392, 4096]) | F16 | | transformer.encoder.layers.27.mlp.dense_4h_to_h.weight | torch.Size([4096, 13696]) | F16 | | transformer.encoder.final_layernorm.weight | torch.Size([4096]) | F32 | | transformer.output_layer.weight | torch.Size([65024, 4096]) | F16 | +---------------------------------------------------------------------+---------------------------+---------+ ggml_init_cublas: found 1 CUDA devices: Device 0: NVIDIA GeForce RTX 2080 Ti, compute capability 7.5 Running on local URL: http://0.0.0.0:7861 To create a public link, set `share=True` in `launch()`.
The inference speed was mentioned in the previous chapter as well.
Thoughts and Conclusion WSL is amazing! Truly a magical tool that can transform the ordinary into the extraordinary! It’s an essential weapon for development on Windows as the main machine! Once YDJSIR get the hang of it, YDJSIR’ll run all my projects in WSL! Thanks to M$ and Huang!
However, it seems that this model may not be well-suited for completing log statements, failing to meet YDJSIR’s expectations. Nevertheless, the experience of exploration remains invaluable.