2023-Fall Advanced Cloud Computing Practice Assignment 2
Hosting Environment
During the machine creation process, SSH passwords were used for authentication. All machines are part of the same virtual switch and the same security group, with all internal communications allowed.
Configuration Process
Basic Environment
Modify Hostname and Configure Hosts
The hostname for each machine has been generated during creation, so no modifications are necessary. Add the following entries to the /etc/hosts file of each host.
Generate an SSH key on the ceph1 machine and then manually distribute it to ceph1, ceph2, and ceph3. Finally, verify the availability of SSH.
Disable Firewall and SELinux
Turn off the firewall.
1 2 3
systemctl stop firewalld systemctl disable firewalld systemctl status firewalld
SELinux is turned off by default.
Configure NTP
Install NTP on each node.
1
yum -y install ntp
Sync the time of ceph2 and ceph3 nodes with ceph1. Modify the /etc/ntp.conf file on ceph2 and ceph3 nodes. Comment out the existing time servers and add ceph1 as the time server.
Start the ntpd service on each node and check its status to ensure it is active.
1 2
systemctl start ntpd systemctl status ntpd
On ceph2 and ceph3 nodes, confirm that the NTP server points to ceph1.
1
ntpq -pn
You should see output similar to the following:
1 2 3 4 5
[root@ceph2 ~]# ntpq -pn remote refid st t when poll reach delay offset jitter ============================================================================== *192.168.0.31 202.118.1.81 2 u 40 64 3 0.181 -0.477 2.802
1 2 3 4 5
[root@ceph3 ~]# ntpq -pn remote refid st t when poll reach delay offset jitter ============================================================================== *192.168.0.31 202.118.1.81 2 u 16 64 3 0.221 -0.623 0.046
Install Ceph
Configure Ceph Repository
Create a new file /etc/yum.repos.d/ceph.repo and set its content as follows:
services: mon: 3 daemons, quorum ceph1,ceph2,ceph3 (age 24s) mgr: ceph1(active, since 9s), standbys: ceph3, ceph2 osd: 0 osds: 0 up, 0 in
data: pools: 0 pools, 0 pgs objects: 0 objects, 0 B usage: 0 B used, 0 B / 0 B avail pgs:
Deploy OSD node
At this point, it was discovered that additional data disks needed to be purchased for each server instance. Therefore, a 40GB cloud disk was added to each server, with the device name set as /dev/sdb. Below is an example of the result on ceph1.
Huawei Cloud will prompt for disk initialization, but this is unnecessary. We do not need to partition or create a file system on these disks. After restarting the three machines, the ceph cluster will start automatically.
Let’s first display the disk status (using ceph1 as an example).
1 2 3 4 5
[root@ceph1 ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 40G 0 disk └─sda1 8:1 0 40G 0 part / sdb 8:16 0 40G 0 disk
Switch to the /etc/ceph directory on ceph1 and execute the following command to add the three newly added disks to the cluster.
[ceph3][WARNIN] Running command: /bin/systemctl enable --runtime ceph-osd@2 [ceph3][WARNIN] stderr: Created symlink from /run/systemd/system/ceph-osd.target.wants/[email protected] to /usr/lib/systemd/system/[email protected]. [ceph3][WARNIN] Running command: /bin/systemctl start ceph-osd@2 [ceph3][WARNIN] --> ceph-volume lvm activate successful for osd ID: 2 [ceph3][WARNIN] --> ceph-volume lvm create successful for: /dev/sdb [ceph3][INFO ] checking OSD status... [ceph3][DEBUG ] find the location of an executable [ceph3][INFO ] Running command: /bin/ceph --cluster=ceph osd stat --format=json [ceph_deploy.osd][DEBUG ] Host ceph3 is now ready for osd use.
At this point, you can check the status of the cluster to see the available space after deployment. Use the following command:
1
ceph -s
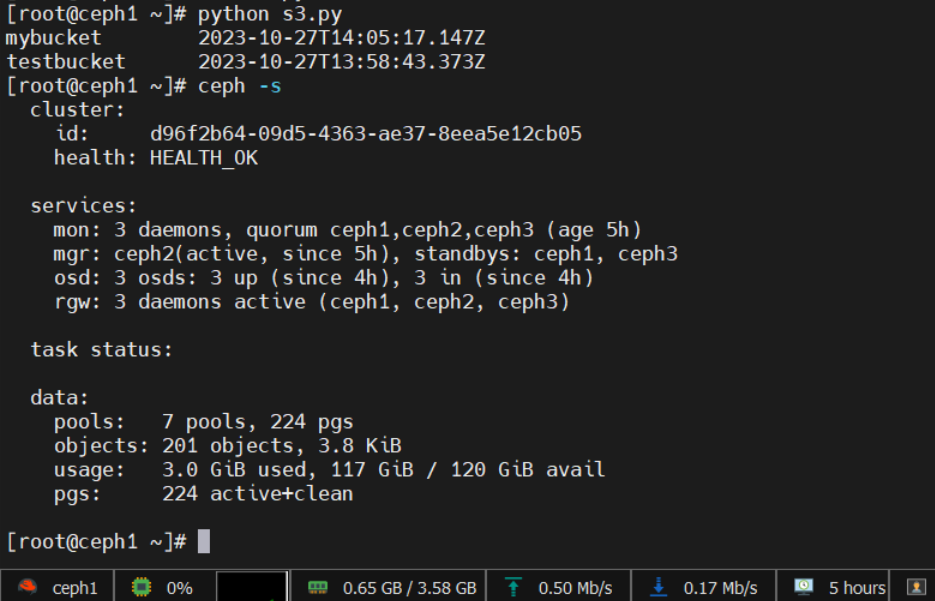
This command will provide you with the current status of the Ceph cluster, including information about the number of OSDs, the total and available space, and the health of the cluster. You should be able to see the newly added storage space reflected in the output.
[root@ceph1 ~]# echo "hello world" > test.txt [root@ceph1 ~]# rados -p pooltest put test ./test.txt [root@ceph1 ~]# rados -p pooltest ls test [root@ceph1 ~]# rados -p pooltest ls -al Please use --output to specify the output file name [root@ceph1 ~]# ceph -s cluster: id: d96f2b64-09d5-4363-ae37-8eea5e12cb05 health: HEALTH_WARN application not enabled on 1 pool(s)
services: mon: 3 daemons, quorum ceph1,ceph2,ceph3 (age 4h) mgr: ceph2(active, since 4h), standbys: ceph1, ceph3 osd: 3 osds: 3 up (since 4h), 3 in (since 4h) rgw: 3 daemons active (ceph1, ceph2, ceph3)
Thus, the S3 interface now supports file uploads and downloads, and the cluster remains healthy.
Testing Phase
In this section, we will use a Python script to test the S3 interface. CentOS comes with python and python3 by default, so no updates are needed. First, install the necessary dependencies.
1
yum -y install python-boto
Next, create a Python file with the following content and run it. This script will create a bucket named mybucket. After running the script, you should see a message indicating that the bucket mybucket has been created successfully, and the cluster should remain healthy.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
import boto import boto.s3.connection access_key = 'test1' secret_key = 'test1' conn = boto.connect_s3( aws_access_key_id = access_key, aws_secret_access_key = secret_key, host = 'ceph1', port= 7480, is_secure=False, calling_format = boto.s3.connection.OrdinaryCallingFormat(), ) bucket = conn.create_bucket('mybucket') for bucket in conn.get_all_buckets(): print"{name}\t{created}".format( name = bucket.name, created = bucket.creation_date)
At this point, the experiment is complete. Make sure to save the images of the three machines on Huawei Cloud for future use. After that, delete and release the resources to finalize this experiment.